Technical overview¶
Worker design¶
See also
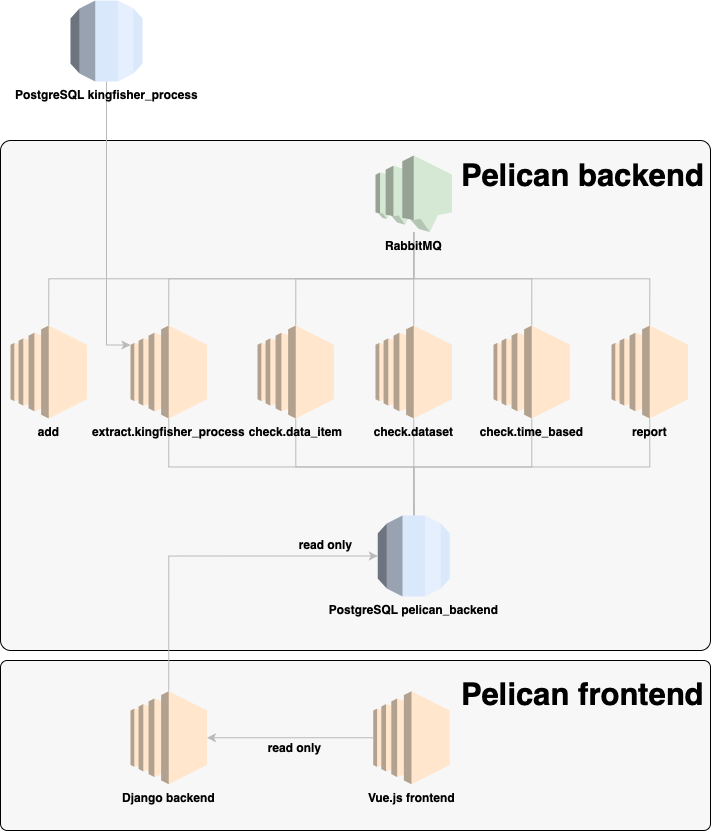
Workers communicate via a RabbitMQ exchange to extract and assess OCDS data, writing the results to a PostgreSQL database.
Workers can be daemonized and run in parallel. The pipeline is:
An extract worker extracts a collection and its compiled releases. It publishes the IDs of the items in batches.
The check.data_item worker performs the field-level and compiled release-level checks. After each batch is processed, it publishes the ID of the dataset.
The check.dataset worker determines whether field-level and compiled release-level checks have been performed on all items. If so, it performs the dataset-level checks. After, it publishes the ID of the dataset.
The check.time_based worker performs the time-based checks. After, it publishes the ID of the dataset.
The report worker creates field-level and compiled release-level reports, picks field-level and compiled release-level examples, and updates the dataset’s metadata.
Repository structure¶
├── contracting_process Field-level and compiled release-level checks
│ ├── field_level Field-level checks
│ │ ├── codelist List inclusion checks
│ │ ├── coverage Coverage checks
│ │ ├── format String format checks
│ │ └── range Range checks
│ └── resource_level Compiled release-level checks
│ ├── coherent Coherence checks
│ ├── consistent Consistency checks
│ └── reference Reference checks
├── dataset Dataset-level checks
│ ├── consistent Consistency checks
│ ├── distribution Distribution checks
│ ├── misc Miscellaneous checks
│ ├── reference Reference checks
│ └── unique Uniqueness checks
├── pelican The main project
│ ├── migrations Database migrations
│ ├── static Static files (SQL dumps, SQL snippets, etc.)
│ └── util Shared utilities
├── time_variance Time-based checks
│ └── checks Individual checks
└── workers :doc:`All workers<reference/workers>`
├── extract Extractor workers
└── check Checker workers
Pelican frontend integration¶
Pelican backend and Pelican frontend are composed as in this image: